Through some reading last evening I stumbled upon an article that described a technique that allegedly sped up large INSERT performance by 50% on Postgres.
The technique revolves around changing the INSERT statement from
INSERT INTO table (f0, ..., fn)
VALUES (f0_v0, ..., fn_v0), ..., (f0_vm, ..., fn_vm)
to
INSERT INTO table (fa, ..., fn)
SELECT * FROM unnest(f0v[], ..., fnv[])
For those unfamiliar with unnest when used in the context of a table expression it can be seen as an analogous to the zip function in Python.
Apparently the speed benefits come from a reduction in time spent planning the query as the unnest technique avoids having to reason about n * m binding parameters (one for each value of each row) as only n homogeneous arrays are passed over for insertion. In other words, the amount of time spent planing the insert is not a function of the number of items anymore which is a desirable property for large inserts.
One point that caught my attention was the author’s statement that
several object-relational mappers use it under the hood
while I knew for sure that Django’s ORM didn’t so I gave it a try to see how invasive such a change would be.
Well I’m happy to report that through the exploration work I identified a potential performance improvement to SQL generating logic which yield a 5% improvement on the query_values_10000.benchmark.QueryValues10000.time_query_values_10000 ASV benchmark and would likely get better if the benchmark was inserting more than one field at a time.
I also managed to get unnest insert working in a non-invasive manner under the following conditions
- It can only be used if all values are literals as an homogeneous array of values must be bound to
unnestparameters. From my experience this is the case most of the time as it’s rare that database expressions are provided for insertion purposes. - It cannot be used when inserting
ArrayFieldbecauseunnestdoesn’t allow to discriminate on the depth of the unnesting (it’s more of a flatten function) so there’s no way to provide a bound parameter that is an array of arrays without creating a custom function.
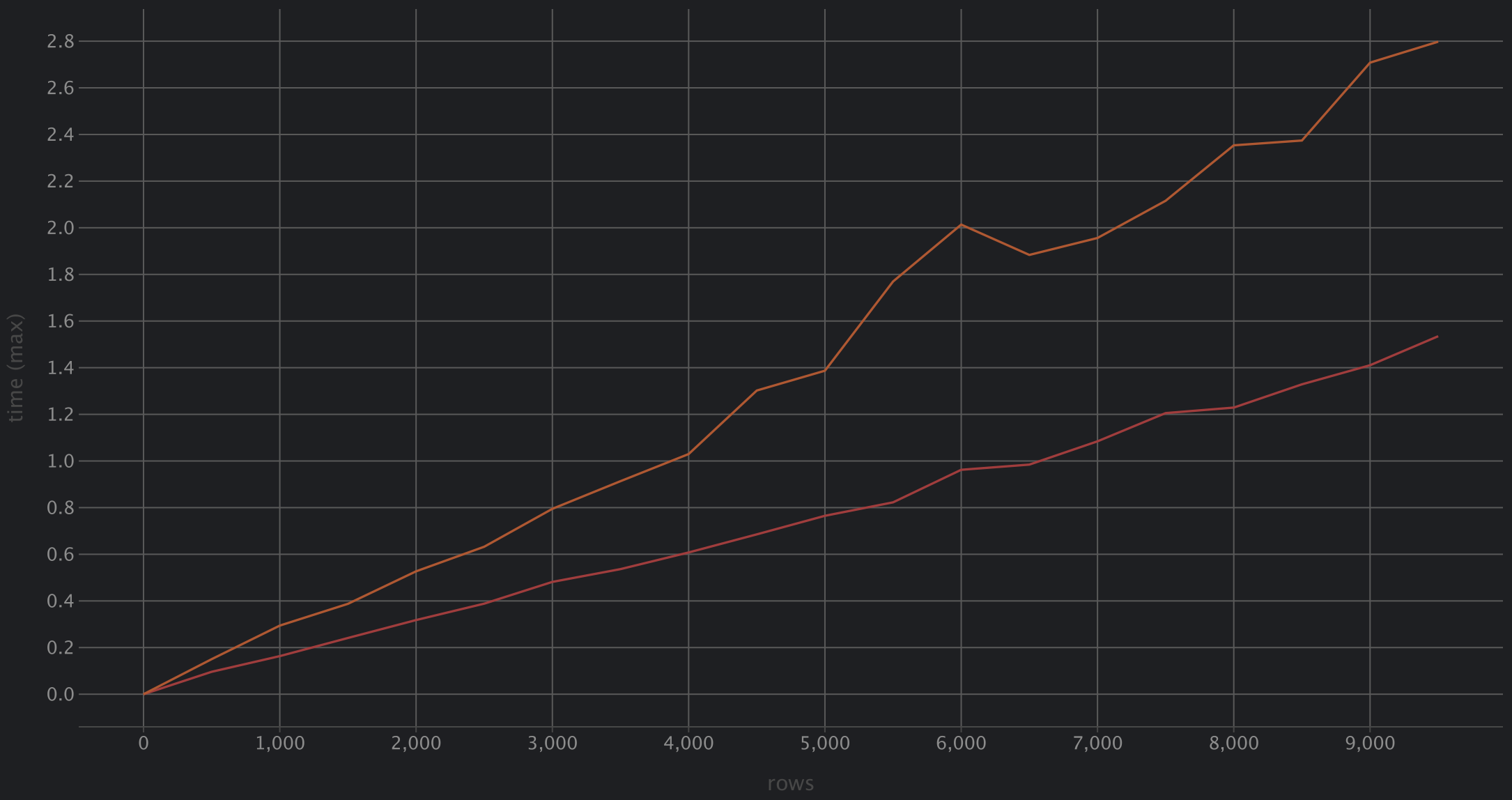
When the proper conditions are met unnest can be used and from my local testing trying to reproduce the article’s author result I can reliably reproduce a 20-25% speed up when using bulk_create to insert 500 rows at a time and no slow down up when using the technique for 2-499 rows.
The great thing about this approach is that it is compatible with all the other options bulk_create support such as ignore_conflicts or update_fields and friends. It’s really just a replacement for VALUES and one binding parameter per field X row and also avoids generating a large string to send over the wire. It also happens to pass the full test suite ![]()
I’m happy to create an optimization ticket out of this branch but I wanted to get some community validation on the merit of the approach and the reproducibility of the results first.
Cheers!