Django Sitemap Best Practice
I have about 200k urls. I set the per page limit to 5000, and page_cache at 86400 (24 hours). The sitemap is dynamically generated by sitemap index (The sitemap framework | Django documentation | Django). It is super helpful.
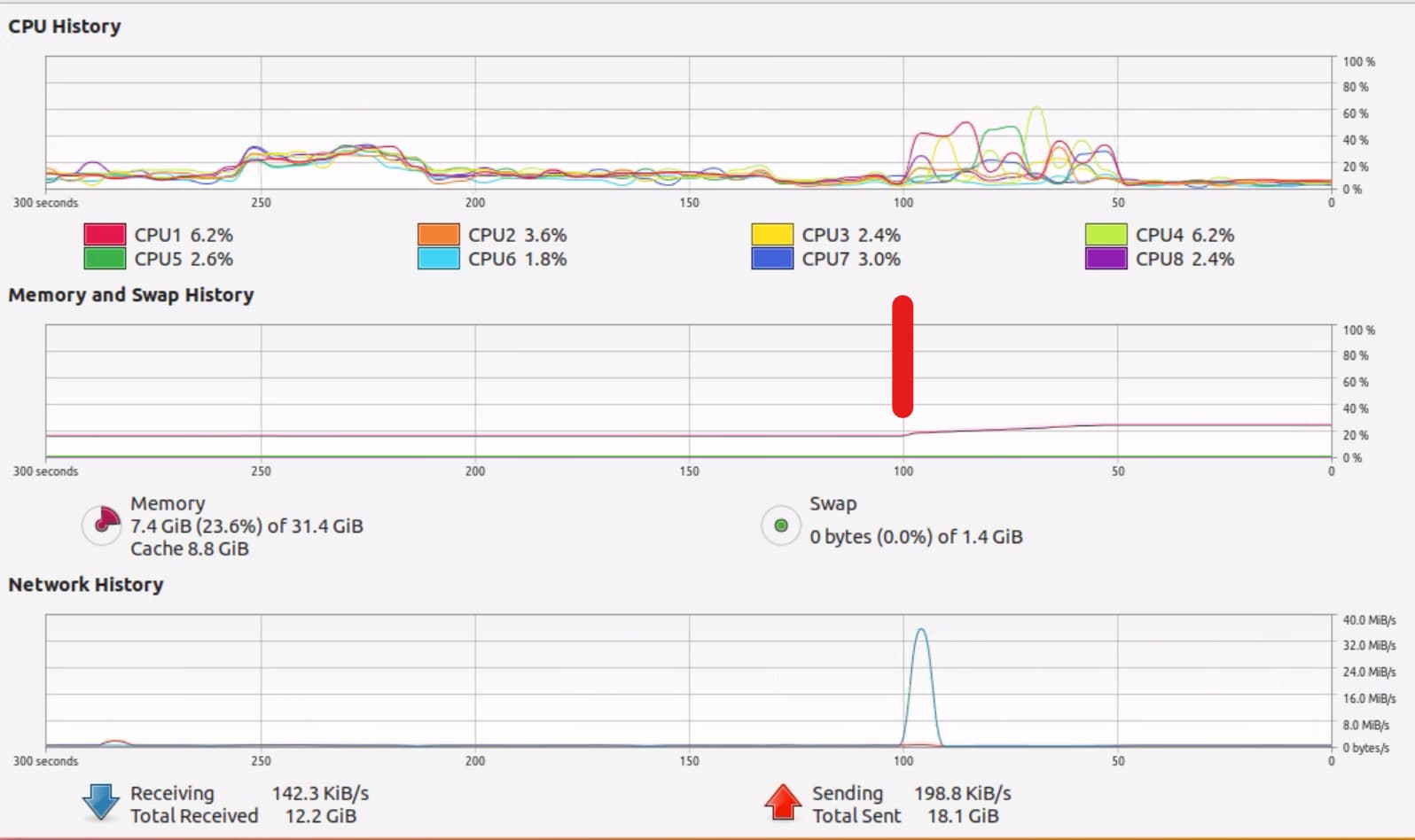
1 problem, example.com/sitemap.xml sometimes crash the server. The AWS EC2 console shows service are ok, but unable to ssh to the server, and web app is down.
I am still testing and not 100% sure about root cause, maybe
- Internal factor, due to EC2, nginx, gunicorn or django
- External factor, because of web crawlers (Googlebot)?
How do you ensure sitemap has high performance? What are the best practices if you have millions of urls? Or the only solution is to increase the server specs?
Would like to hear your experience.
Sitemap items
from django.contrib.sitemaps import Sitemap
from blog.models import Entry
class BlogSitemap(Sitemap):
changefreq = "never"
priority = 0.5
def items(self):
return Entry.objects.filter(is_draft=False)
def lastmod(self, obj):
return obj.pub_date
Is there anything we can do on the queryset to improve performance, such as selecting specific fields (urls, last_modified). Or since it’s lazy, it’s already optimized?
Cache
I am using page_cache, are there any tips that would make a difference?
Compress sitemap
1 technique is to create sitemap with .gz extension.
If we create the .gz files ourselves, how do we integrate that with the sitemap index?
Cached vs compressed sitemap performance
Is compressed sitemap more performant than cached sitemap?
What are the pros and cons?