I’m going to share my experience with this, is not totally related to your setup, but i think this may help someone on the wild later on (possibly me).
TL:DR:
Don’t have a proccess that uses the database, and have it idle for a long time on AWS RDS. It will mess up with the connection.
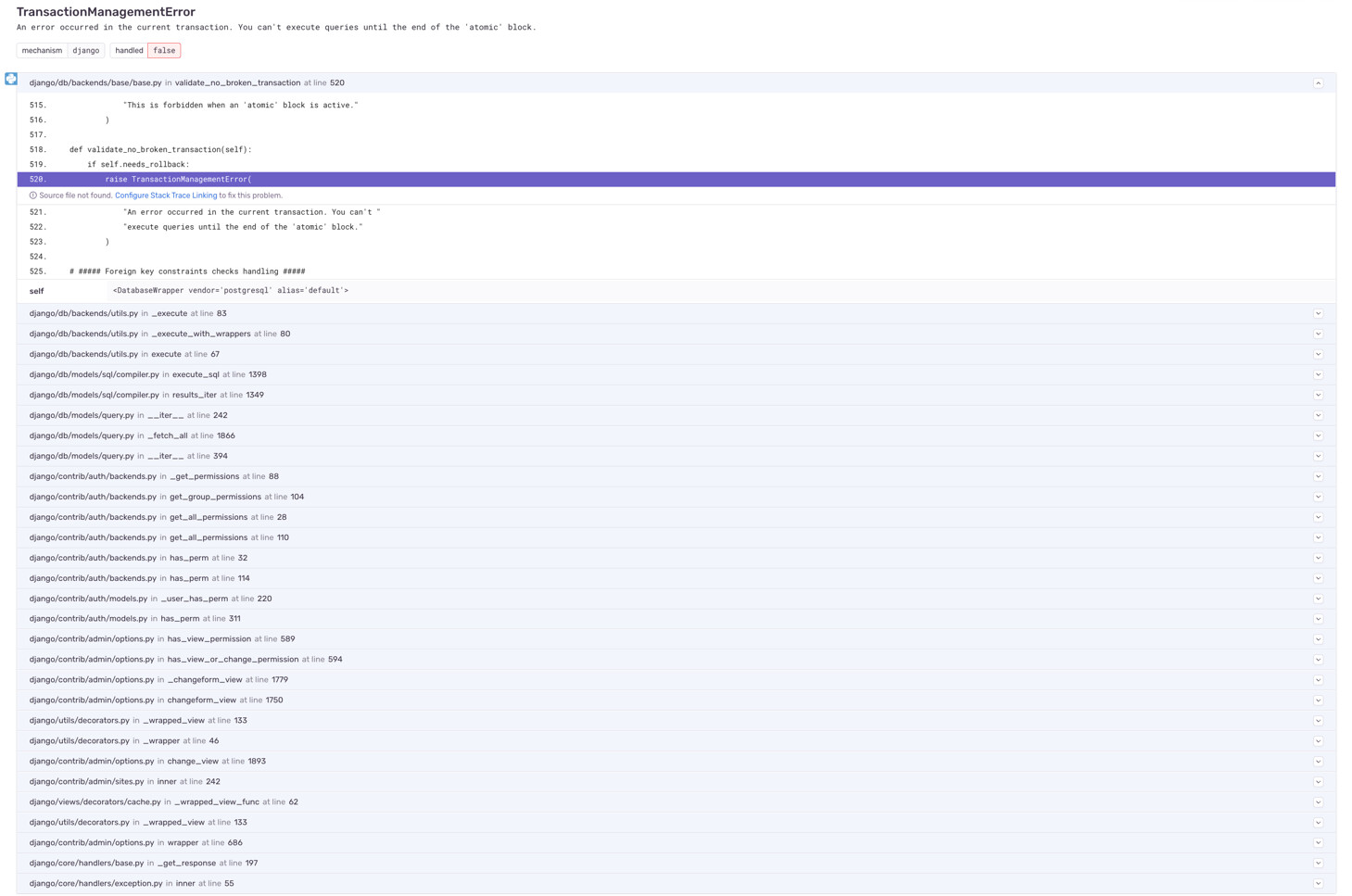
I was experiencing a issue that after some time my celery beat (scheduler) was receiving an:
django.db.utils.InterfaceError: cursor already closed and i was trying to figure it out what was causing this in the first place. So before the details, here’s my setup:
Python 3.11
# Python deps
Django==4.2.8
celery[redis]==5.3.6
psycopg2-binary==2.9.9
django-tenants==3.6.1
tenant-schemas-celery==2.2.0
# DB
PostgreSQL 16 (local)
AWS RDS (production)
So, for those that haven’t used tenant-schemas-celery before, basically all we need to know is that for every Celery task that is “beaten” (produced/enqueued) the beat proccess queries the database for all the tenants to produce that task. And this is where the errors where being raised.
After an hour that the proccess was running, it received this error. Then the proccess was restarted and everything’s working again. And again, after one hour the same error is raised.
Here’s my beat_schedule config, for reference:
CELERY_CONFIG = {
# ... other configs ...
"beat_schedule": {
"discover_communication_accounts_every_day_03_01_utc": {
"task": "comms.tasks.discover_communication_accounts",
# https://crontab.guru/#0_3
"schedule": crontab(minute="1", hour="3"),
"options": {"expires": timedelta(days=1).total_seconds()},
},
"niko_niko_check_every_30_minutes": {
"task": "niko_niko.tasks.niko_niko_send_to_all_employees",
# https://crontab.guru/every-30-minutes
"schedule": crontab(minute="*/30"),
"options": {"expires": timedelta(minutes=29).total_seconds()},
},
"employee_send_video_exercise_every_30_minutes": {
"task": "exercises.tasks.exercise_send_to_all_employees",
# https://crontab.guru/every-30-minutes
"schedule": crontab(minute="*/30"),
"options": {"expires": timedelta(minutes=29).total_seconds()},
},
},
}
So here’s how i tried to solve this issue:
-
Verified the CONN_MAX_AGE configuration. Initially this value was not set on my configuration file, i tried some other values directly on production, like: 0 (Closing the connection after the usage, but i guess that nothing was actually closing the session, i monkey-patched the close method of the db Backend and no one was calling it), explicitly setting to None and other small integer values. None of these options made any effect, the error still happened after the exact same time.
-
I tried to reproduce this behavior locally, but didn’t get the same behavior. So something was messing up with the connection on the production database only, and after some time.
-
I noticed that my beat proccess was idle most of the time for the one-hour time span before the error happens, this happens because right now i only have some periodic tasks that happens at the “same time” (every half hour, minutes 0 and 30 of every hour), and the first execution was working flawlessly. But after this first execution the beat proccess would not use the database for ~29 minutes. And on the second execution (almost an hour after the process is started) the connection was broken, raising the error mentioned. So after this, i tried changing my beat_schedule configuration a bit, and changed one of the entries to run every minute, and after this change i didn’t get these errors after one hour.
So my conclusion is that: AWS RDS is closing (or messing up) with the connection because it’s “idle” for a long time. And the solution for me is to have a more “periodic” periodic tasks. I can’t have my beat process idle for that much time, otherwise the connection will be terminated, or interrupted.