Hi everyone,
I have a Sale model table (a legacy table that I only have read permission) that keeps all the sale records. If I need to make a query that aggregate 300,000 members their last 6 months purchase total amount (last 6 months meaning that “purchasedate__range=(max(purchase_date) - 6 * 30, max(purchase_date))”, so each member has their own purchase period. The queryset in dataframe look like the following:
member | start_date | end_date | total_amount
1111111| 2021-01-03 | 2021-06-02 | 1234
1111112| 2021-02-03 | 2021-07-02 | 2345
1111113| 2021-03-03 | 2021-08-02 | 3456
.
.
.
1234565| 2022-03-03 | 2022-08-02 | 9999
It would be quite easy to accomplish this using left join by directly accessing database using DB editor. e.g. SSMS
=========================================
select MemberID
, max(PurchaseDate) as MaxPurchaseDate
, dateadd(month, -6, max(PurchaseDate)) as StartDate
, max(PurchaseDate) as EndDate
into #Last6Month
from dbo.SalesTable
group by MemberID
select a.MemberID
, sum(Amount) as TotalAmount
from dbo.SaleTable as a
left join #Last6Month as b
on a.MemberID = b.MemberID and b.PurchaseDate between a.StartDate and a.EndDate
where b.MemberID is not null
group by a.MemberID
=========================================
But i found it difficult in doing this in django orm. The main reason is that I found it difficult to have join operations for unrelated tables (in my case a temp table with the Sale table itself). I have tried to use chain Q() to build q |= Q(**{‘memberid’: row[‘memberid’], ‘purchasedate__range’:[row[‘start_dfate’],row[‘end_date’]]}), but it failed because of retrieving 300,000 members in this way is too big for django orm, plus it’s basically used WHERE clause with 300,000 members with their specific periods that is very inefficient. It worked for 25,000 members but not for 300,000 members.
Is there anyone has a better idea for me would be very appreciated, thanks.
Kelvin
If I’m understanding the situation correctly, you’re not really joining two tables here. You’re aggregating data within a subset of that table. (Think “Subquery” instead of “join”)
So I did some playing around, and I think this might be on the right track.
First, assume the model:
class Sale(models.Model):
member = models.CharField(max_length=10)
purchase_date = models.DateField()
amount = models.IntegerField(default=0)
First, we’ll define a subquery to get the last purchase date for each member.
subq = Subquery(
Sale.objects.values('member'
).annotate(max_date=Max('purchase_date')
).filter(member=OuterRef('member')
).values('max_date')
)
Now, we can write a query using that information to get the Sale instances within the proper range:
queryset = Sale.objects.annotate(mdt = subq
).filter(purchase_date__lte=F('mdt'),
purchase_date__gte=F('mdt')-timedelta(days=180)
).values('member'
).annotate(total=Sum('amount')
).order_by('member')
Given the following data:
Member | Purchase date | Amount
1111 | 2023-06-12 | 30
1111 | 2024-06-12 | 20
1111 | 2024-07-12 | 10
1112 | 2024-01-12 | 50
1112 | 2024-05-12 | 40
1112 | 2024-07-15 | 80
1112 | 2024-08-12 | 70
1112 | 2024-12-12 | 60
That query produces:
<QuerySet [{'member': '1111', 'total': 30}, {'member': '1112', 'total': 210}]>
Now, I have absolutely no idea how performant this would be on a table containing 300,000 rows. At a minimum I’m going to guess you’re going to want indexes on both the member and purchase_date columns.
But hopefully this gives you another direction in which to work.
Hi Ken,
Thank you for your response.
But when I applied the same logic using subquery, I was unable to get the results as you did (not sure if I did it correctly or not  ) and the following error occurred:
) and the following error occurred:
Error: “DB::Exception: Scalar subquery returned more than one row: While processing …”.
I was wondering if “mdt” in “queryset = Sale.objects.annotate(mdt = subq …” needs a scalar value instead but “subq” returns a list of max_date causing the error.
Really appreciated your answer.
Kelvin
Besides, I was wondering if subquery supports a table instead of a column? Such as the following?
subq = Subquery(
Sale.objects.values(‘member’
).annotate(max_date=Max(‘purchase_date’)
).filter(member=OuterRef(‘member’)
).values(‘member’,‘max_date’)
)
Then subq can be used in Sale.objects.annotate() or Sale.objects.filter()?
Kelvin
To answer your second question first, no - at least not directly. A subquery used in an annotation must return 1 value. See the docs for Subquery for more details.
Do you have the two values clauses in your subquery?
Can you post the actual query you tried? I might be able to help if I can see it. Also note that if your model isn’t structurally similar to my assumed model, there are other changes that may need to be made, so seeing the model(s) involved would help.
Hi Ken,
I don’t have Sale model at hand, but I have another model table ‘Price’ that can be used to mimic the sale case and demostrate the problem I am facing.
Price model
The Price model has data as follows:
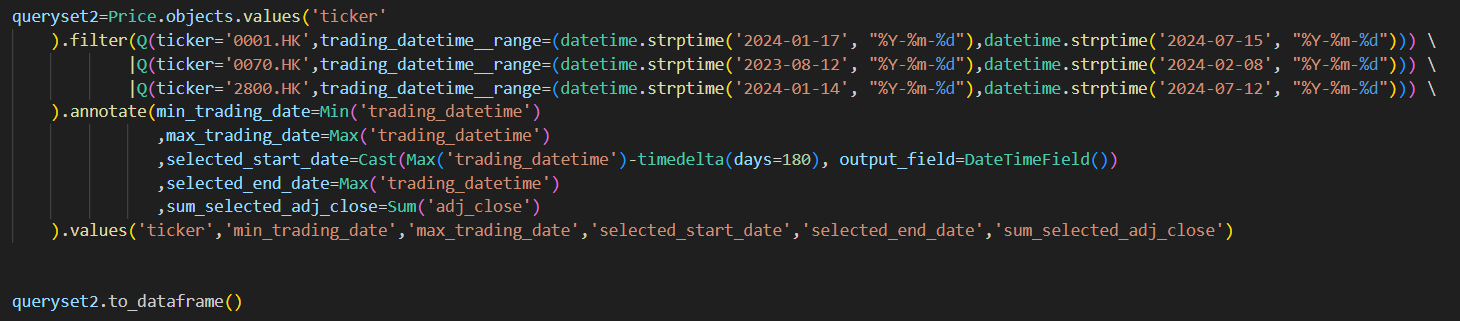
I am using 3 tickers as an example, if I aggregate these 3 tickers, we can find their minimum and maximum trading date, and the sum of close price that corresponds to these min max trading periods (it’s just an example for demo only, usually we don’t sum close price  ). But what I really need is to calculate the sum of close price based on their individual last 6 months periods (see selected_start_date and selected_end_date) and last 6 months periods of each stocks are not the same.
). But what I really need is to calculate the sum of close price based on their individual last 6 months periods (see selected_start_date and selected_end_date) and last 6 months periods of each stocks are not the same.
If I implemented the requirement logic in orm, it will look like the following.
After filtering based on the stocks and their corresponding selected periods using chain Q(), the min_trading_date and max_trading_date will be the same as selected_start_date and selected_end_date. The ‘sum_selected_adj_close’ turns out that is the aggregated values I eventually need. However, the situation is getting difficult when the number of stocks say increasing to 300,000.
So I was wondering if you know any way that can solve this situation?
Thank you for your help in advance.
Kelvin
So one of the potential factors here is that you are using a custom manager.
Does this manager alter the standard queryset in any way? If so, that could be interfering with what you’re trying to do here. (If not, if the only definitions within the manager are extra query functions, then that shouldn’t be an issue.)
Again, my gut hunch is that a subquery is your best chance of a solution here, with the caveat that if you’re unable to add indexes to the tables, I don’t think anything you do within an ORM query is going to do you much good because you will end up needing to do table scans regardless of the query being written.
You could take a look at the django-cte package to see if a solution using it is more effective.
Side note: Please don’t post images of code or other textual data here. Copy/paste the text into the body of your post, surrounded between lines of three backtick - ` characters. This means you’ll have a line of ```, then the code (or other text), then another line of ```. This forces the forum software to keep the existing text formatting. (That’s how I did the sample table above.)
Hi Ken,
Thank you for your hints. I managed to solve it by using ‘django-cte’ 
You save me day, thanks.
Kelvin
it’s too late, but i think it’s possible without django-cte.
solution is just add filtering pk option.
because it worked in less than 300,000 rows.
l = []
for i in range(300000)[::20000]:
l += list(Price.objects.filter(pk__gte=i, pk__lte=i+20000, {your filter})
for i in l: print(i.__dict__)
Hi Seolpyo,
It’s never too late and I really appreciate you keep trying to find a better solution for my case.
Unfortunately, my question also has to fulfill one more condition which is kept the data type as queryset so that the query results can be used by others and let the others to decide what datatype they like to convert to by queryset.
By using for loop with list can be a solution if without the condition I mentioned above.
Anyway, very appreciate to have your input on it.
Kelvin
if you need queryset, it’s simple.
just 1 more request to database.
for loop is just check data. not any means.
l = []
for i in range(300000)[::20000]:
l += list(Price.objects.filter(pk__gte=i, pk__lte=i+20000, {your filter}).value_list('pk', flat=True)
p = Price.objects.filter(pk__in=i)
print(len(l))
print(p.count())
let me try it tomorrow and give you feedback