Hello,
I would like to seek clarification regarding ticket #5929, which has been marked as a duplicate of the recently closed ticket #373. My concern is whether the work we are doing on ticket #5929 remains relevant in light of the closure of ticket #373.
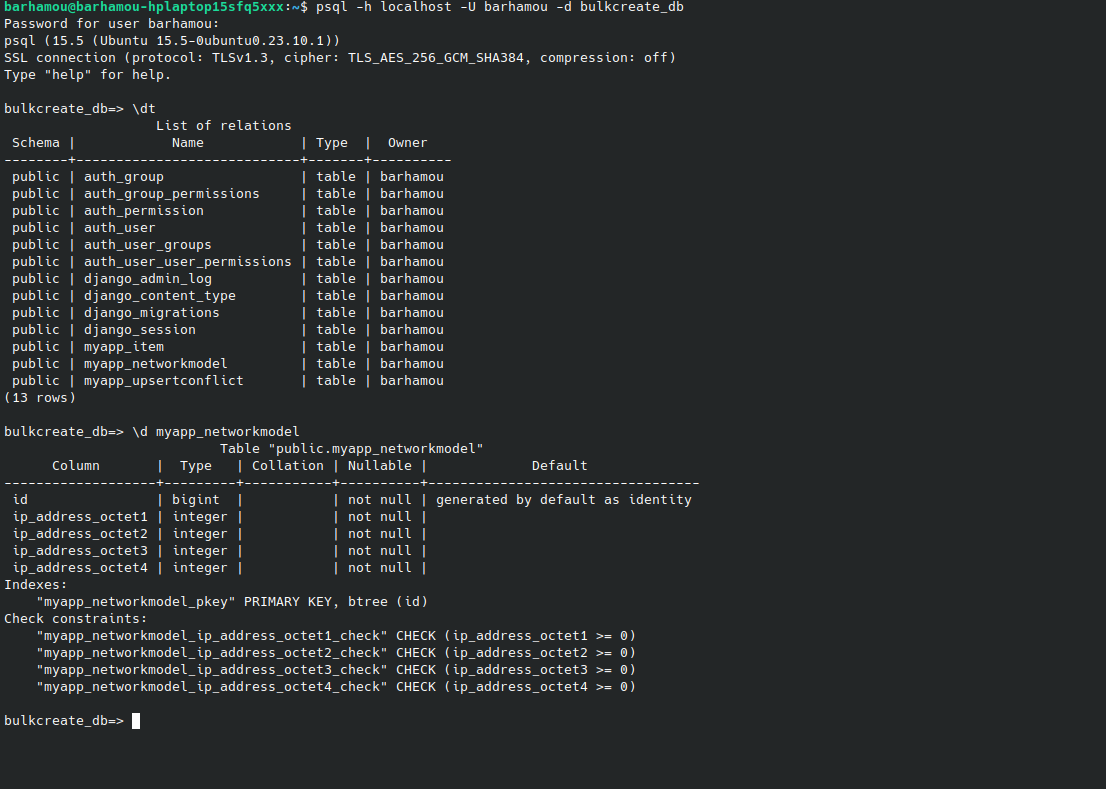
Our work on ticket #5929 focuses on developing a generalized MultiColumnField. To this point, we have successfully created this additional field, generated corresponding migrations, and established columns in the database following a specific naming convention. This effort aims to provide a general framework for MultiColumnField that can be adapted to various use cases, with IP address serving as an example application.
However, given that ticket #5929 has been identified as a duplicate of ticket #373, we would like to understand:
- Why was ticket #5929 identified as a duplicate of ticket #373? The objectives and approaches of both tickets seem similar but with different applications.
- Is it still relevant to continue work on ticket #5929, or should we shift our focus towards the discussions and solutions considered in ticket #373?
- Are there any specific directions or recommendations from the Django team to ensure that our contribution on ticket #5929 remains aligned with the overall goals of the Django project?
We are committed to making a meaningful contribution to Django and want to ensure that our efforts are in line with the needs of the community.
Thank you in advance for your feedback and guidance.
here are my advances on tiket #5929
an example of a model
from django.db import models
from django.utils import timezone
class Item(models.Model):
name = models.CharField(max_length=100)
last_updated = models.DateTimeField(auto_now=True)
created_at = models.DateTimeField(auto_now_add=True)
price = models.DecimalField(max_digits=10, decimal_places=2)
original_price = models.DecimalField(max_digits=10, decimal_places=2)
stock = models.IntegerField()
update_interval = models.DurationField(default=timezone.timedelta(days=1))
class UpsertConflict(models.Model):
number = models.IntegerField(unique=True)
rank = models.IntegerField()
name = models.CharField(max_length=15)
class NetworkModel(models.Model):
ip_address = models.MultiColumnField(sub_fields={
'octet1': models.PositiveIntegerField(),
'octet2': models.PositiveIntegerField(),
'octet3': models.PositiveIntegerField(),
'octet4': models.PositiveIntegerField()
}, separator='__')
def __str__(self):
return f"{self.octet1}.{self.octet2}.{self.octet3}.{self.octet4}"
the implementation of the MultiColumnField class
class MultiColumnField(Field):
def __init__(self, *args, **kwargs):
self.separator = kwargs.pop("separator", ".")
self.sub_fields = kwargs.pop("sub_fields", {})
if not isinstance(self.sub_fields, dict):
raise ValueError("sub_fields must be a dictionary.")
super().__init__(*args, **kwargs)
self.sub_field_names = {} # Initialisé dans contribute_to_class
def contribute_to_class(self, cls, name, private_only=False, **kwargs):
super().contribute_to_class(cls, name, private_only=True, **kwargs)
# Initialisation des sous-champs avec la convention de nommage
for field_name, field in self.sub_fields.items():
prefixed_field_name = f"{self.name}_{field_name}"
self.sub_field_names[field_name] = prefixed_field_name
field.set_attributes_from_name(prefixed_field_name)
field.contribute_to_class(cls, prefixed_field_name)
def get_prep_value(self, value):
# Préparer les données pour l'insertion dans la base de données
if isinstance(value, str):
# Décomposer la valeur en utilisant le séparateur
parts = value.split(self.separator)
value = {
field_name: part for field_name, part in zip(self.sub_fields, parts)
}
return {
self.sub_field_names[field_name]: field.get_prep_value(value[field_name])
for field_name, field in self.sub_fields.items()
}
def from_db_value(self, value, expression, connection):
# Reconstruire la valeur à partir des sous-champs
reconstructed_value = self.separator.join(
str(value[self.sub_field_names[field_name]])
for field_name in self.sub_fields
)
return reconstructed_value
def get_db_prep_value(self, value, connection, prepared=False):
# Préparation des données pour la base de données
return {
self.sub_field_names[field_name]: field.get_db_prep_value(
value[field_name], connection, prepared
)
for field_name, field in self.sub_fields.items()
}
""" def db_type(self, connection):
# Indique à Django qu'il n'y a pas de colonne de base de données directement associée
return None """
def get_col(self, alias, output_field=None):
# Retourner None ou une représentation adaptée pour le champ complexe
return ''
migration generate
# Generated by Django 5.1.dev20231209152046 on 2023-12-10 21:15
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('myapp', '0002_upsertconflict'),
]
operations = [
migrations.CreateModel(
name='NetworkModel',
fields=[
('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('ip_address_octet1', models.PositiveIntegerField()),
('ip_address_octet2', models.PositiveIntegerField()),
('ip_address_octet3', models.PositiveIntegerField()),
('ip_address_octet4', models.PositiveIntegerField()),
],
),
]
my data base